This paper explores a situation in which an audio stream, produced in real time by a live musician, is used as a source of timbral control over another, synthetic audio stream produced by a computer. Our goal is somehow to project the musician's `intentionality' onto the synthetic audio output. (This might be possible even if, as seems likely, we can never extract or even understand this `intentionality' in pure form.) It is by no means necessary (and most often not desirable or even possible) to do so by trying to recreate the time-varying pitch, loudness, and timbre of the musician's sound exactly. Rather, we wish somehow to make the output sound reflect changes in these, in a way the musician can control in order to produce an interesting stream of synthetic sound.
A related possibility is to make synthetic sounds that follow the `shape' of an unwitting sound source, as a way of highlighting or drawing attention to the music latent in, for example, the voice of a child playing or of a politician dissembling.
A well-known example of this family of techniques is the vocoder, which, in its musical application, estimates the spectral envelope of the incoming sound and applies it as a filter on some other sound. Similarly, it is possible to use a measured spectral envelope to control the amplitudes of an additive synthesis bank. In these two examples, the pitch content of the output, roughly speaking, comes from the filter source or from the frequencies of the sinusoids, whereas variations in timbre and in loudness come from the live performer.
These two examples rely on a high-dimensional timbral estimate, and it is worth considering a situation at the opposite extreme to understand the possibilities, as well as the limitations, that emerge in a very low-dimensional situation. We'll take a somewhat familiar situation in which the synthesis method is simply to retrieve pre-stored music. This has already been explored in a musical context [MoonMoon2001], and the idea of retrieving sounds according to how well their spectra match a desired spectrum was demonstrated in r-xiang02. Many ideas from Xiang's work, in which drum patterns were rearranged according to their spectra to imitate other ones, reappear in the project reported here.
Extensive work has also been done in the context of music retrieval, in which a typical challenge is to identify specific, desired, pieces of music in a huge database [TzanetakisTzanetakis2002]. Here we will use a small enough database that we don't need to use advanced search techniques.
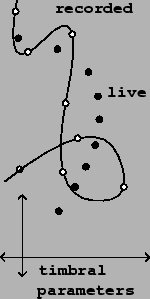
Figure 1 shows diagrammatically a situation in which we want to use a time-varying, live sound to control retrieval of a pre-recorded one. The recorded sound appears as a parametric curve in a (many-dimensional) timbre space; the span of the curve serves as the one available synthesis parameter. The musician's live input appears as another curve in the same space, this one parametrized by real time.
(Although the figure shows the recorded sound as self-intersecting, this is only an artifact of the two-dimensional figure; in a higher-dimensional timbre space the recorded sound might nearly cross itself at many points, but would not be expected to do so exactly.)
As the figure suggests, one possible approach to making the synthetic output follow the live input, assuming we have a reasonable distance measure, would be to output the segment of recorded sound closes to each new point in the `live' curve. Before discussing the ramifications of this approach we will need to develop a set of reasonable criteria for success.