Figure 5.1 introduces a way of visualizing the spectrum of an audio signal. The spectrum shows how the signal's power is distributed into frequencies. (There is a real mathematical definition of the idea, but it requires much mathematical background that can't be assumed here.)
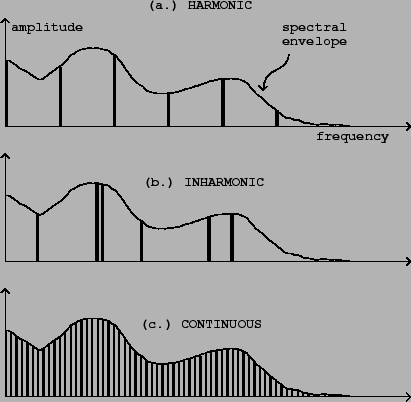 |
Part (a) of the figure shows the spectrum of a
harmonic signal, which is a
periodic signal whose fundamental frequency is in the range of
perceptible pitches, roughly between 50 and 4000 Hz. The FOURIER
SERIES (page ![]() )
gives a description of a periodic signal as a sum of sinusoids. The
frequencies of the sinusoids are in the ratio
)
gives a description of a periodic signal as a sum of sinusoids. The
frequencies of the sinusoids are in the ratio ![]() . (The constant term in the Fourier series may be
thought of as a sinusoid,
. (The constant term in the Fourier series may be
thought of as a sinusoid,
For a harmonic signal, the power shown in the
spectrum is concentrated on a discrete subset of the frequency axis
(a discrete set consists of isolated points, only finitely many per
unit). We call this a discrete
spectrum. Furthermore, the frequencies where the signal's power
lies are in the ![]() ratio that arises from a
periodic signal. (Note that it's not necessary for all of
the harmonic frequencies to be present; some harmonics may have
zero amplitude.)
ratio that arises from a
periodic signal. (Note that it's not necessary for all of
the harmonic frequencies to be present; some harmonics may have
zero amplitude.)
The graph of the spectrum shows the amplitudes of the partials of the signals. Knowing the amplitudes and phases of all the partials would allow us to reconstruct the original signal.
Part (b) of the figure shows a spectrum which is
also discrete, so that the signal can again be considered as a sum
of a series of partials. In this case, however, there is no
fundamental frequency, i.e., no audible common submultiple of all
the partials. We call this an
inharmonic signal. (We'll use the terms ![]() and
and ![]() to describe the
signals' spectra, as well as the signals themselves.)
to describe the
signals' spectra, as well as the signals themselves.)
In dealing with discrete spectra, we report each
partial's RMS amplitude (section 1.1), not its peak amplitude. So
each component sinusoid,
Part (c) of the figure shows a third possibility, which is that the spectrum might not be concentrated into a discrete set of frequencies, but instead might be spread out among all possible frequencies. This can be called a continuous, or noisy spectrum. Spectra don't have to fall into either the discrete or continuous categories; they may be mixtures of the two.
Each of the three spectra in the figure shows a continuous curve called the spectral envelope. In general, sounds don't have a single, well-defined spectral envelope; there may be many ways to draw a smooth-looking curve through a spectrum. On the other hand, a spectral envelope may be specified intentionally by an electronic musician. In that case, it is usually clear how to make a spectrum conform to the specified spectral envelope. For a discrete spectrum, for example, we could simply read off, from the spectral envelope, the desired amplitude of each partial and make it so.
For discrete spectra, the pitch is primarily encoded in the frequencies of the partials. Harmonic signals have a pitch determined by their fundamental frequency; for inharmonic ones, the pitch may be clear, ambiguous, or absent altogether, according to complex and incompletely understood rules. A noisy spectrum may also have a perceptible pitch if the spectral envelope contains one or more narrow peaks.
In this model the timbre (and the loudness) are mostly encoded in the spectral envelope. The distinction between continuous and discrete spectra is also a distinction in timbre. The timbre, as well as the pitch, may evolve over the life of a sound.
We have been speaking of spectra here as static entities, not considering whether they change in time or not. If a signal's pitch and timbre are changing over time, we would like to think of the pitch and spectrum as descriptions of the signal's momentary behavior, which can also change over time.
This way of viewing sounds is greatly oversimplied. The true behavior of audible pitch and timbre has many aspects which can't be explained in terms of this model. For instance, the timbral quality called ``roughness" is sometimes thought of as being encoded in rapid changes in the spectral envelope over time. This model is useful nonetheless in discussions about how to construct discrete or continuous spectra for a wide variety of musical purposes, as we will begin to show in the rest of this chapter.